Level up your Forecasting
Quantify uncertainty with distributional forecasts
R
statistics
time series
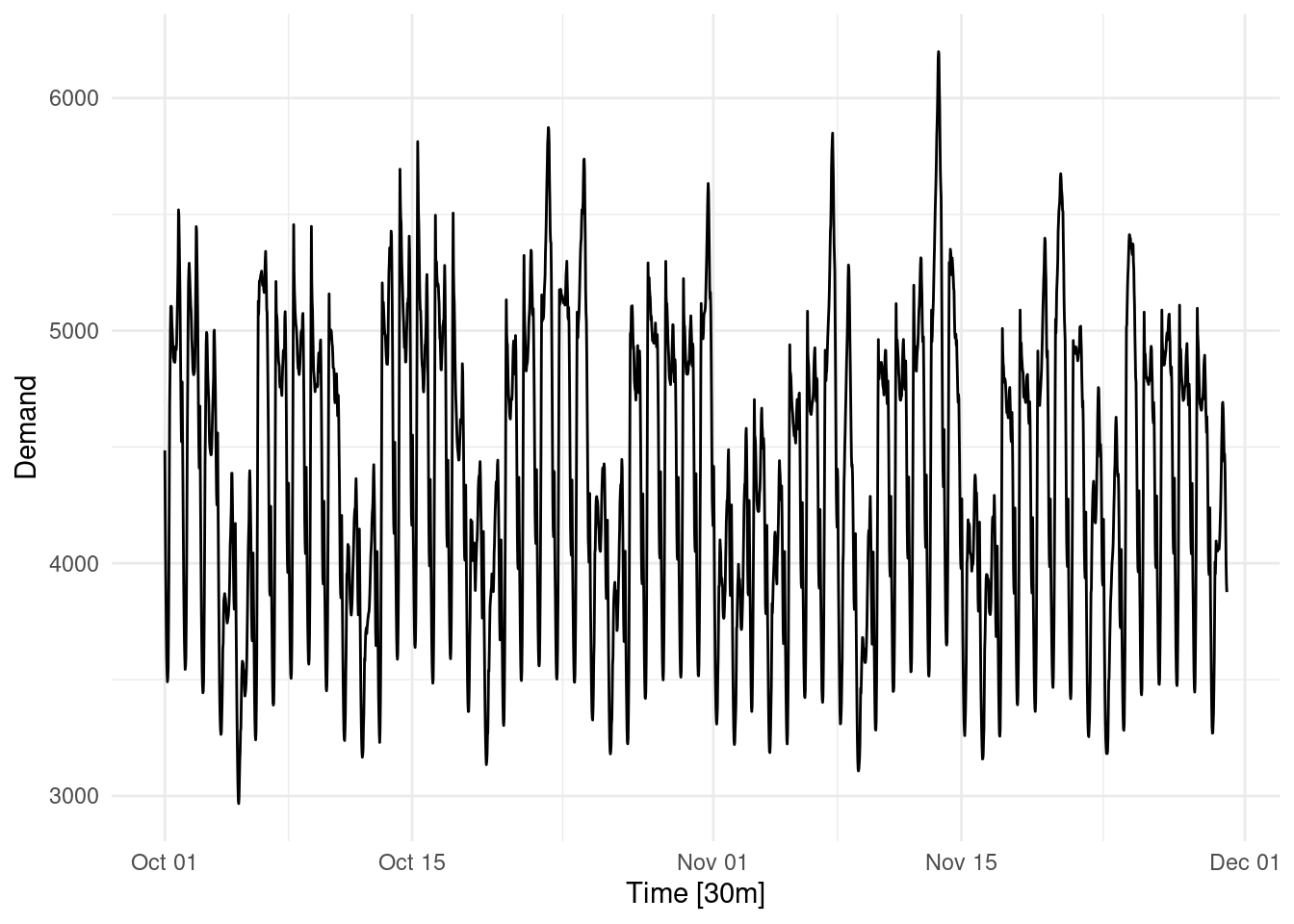
This is a time series data set of half-hourly electricity demand for Victoria, Australia 1. You may not care about electricity forecasting, but there is probably some similar time series in your organisation you do care about.
What is the forecast demand for the next week?
Who knows? I certainly don’t know, despite doing forecasting for a job.
In fact, anyone who tells you they do know (with certainty) is wrong.
But I need to make a forecast, so what do I do?
Often you have to come up with something. Finance needs an estimate of sales or budgets, or your manager needs something to take to the board. So you have to churn out some numbers. But what numbers?
Here are two extremes:
- You could ignore all historical data and just use the most recent data point as the most reliable forecast.
- You could ignore any specific value and just take the average of everything.
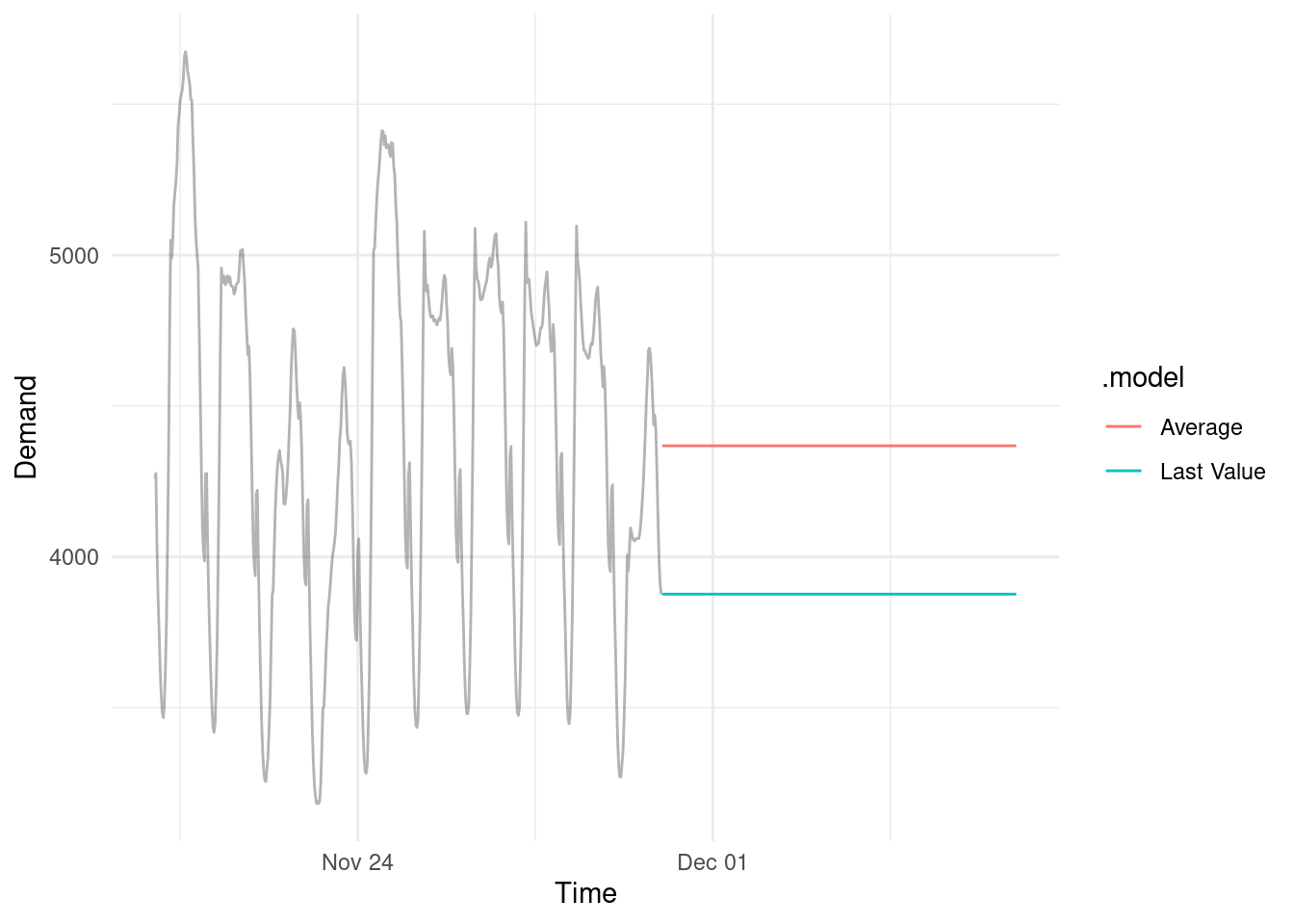
Both are in the ballpark but they aren’t very squiggly like the real data. They clearly aren’t capturing the seasonality.
You could be lazy (clever) and just use the same time period from last week as your current forecast. It actually looks really good. But it’s just one, fixed realization of what could happen. Will it play out exactly like your forecast? Exactly like last week? Almost certainly not.
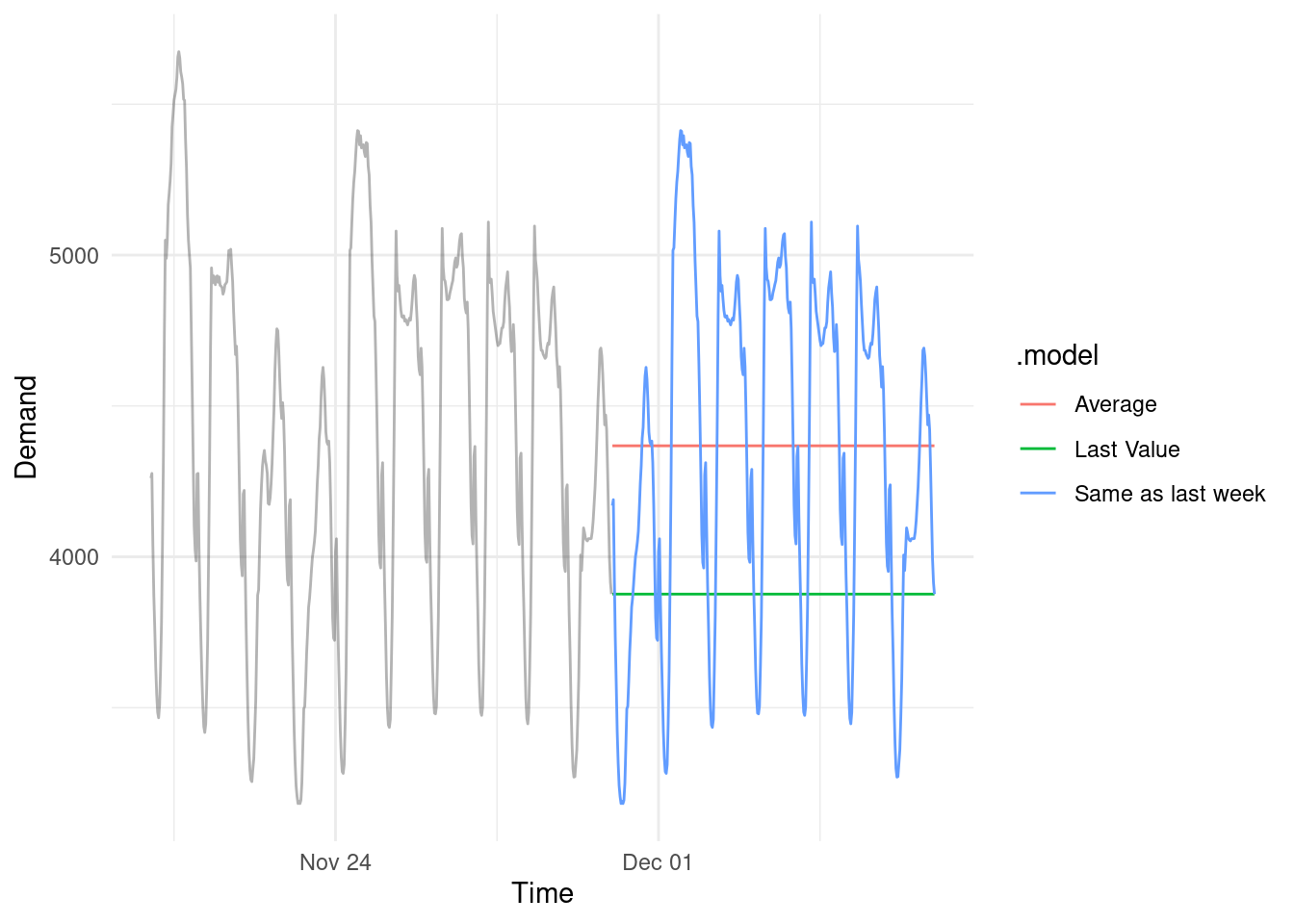
Let’s simulate another way history could play out. (By statistically resampling the residuals in the training data)
And another
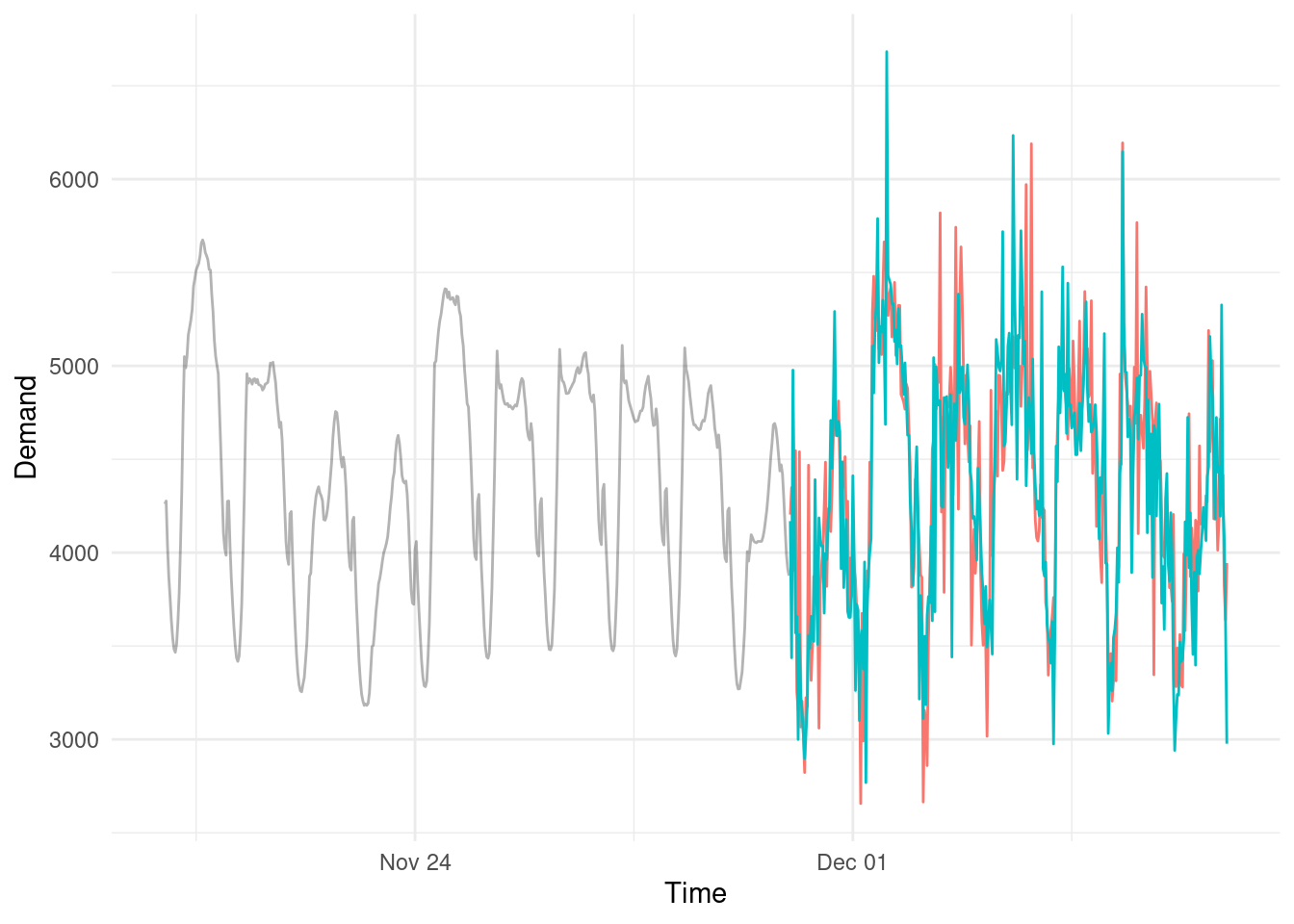
And 20 more:
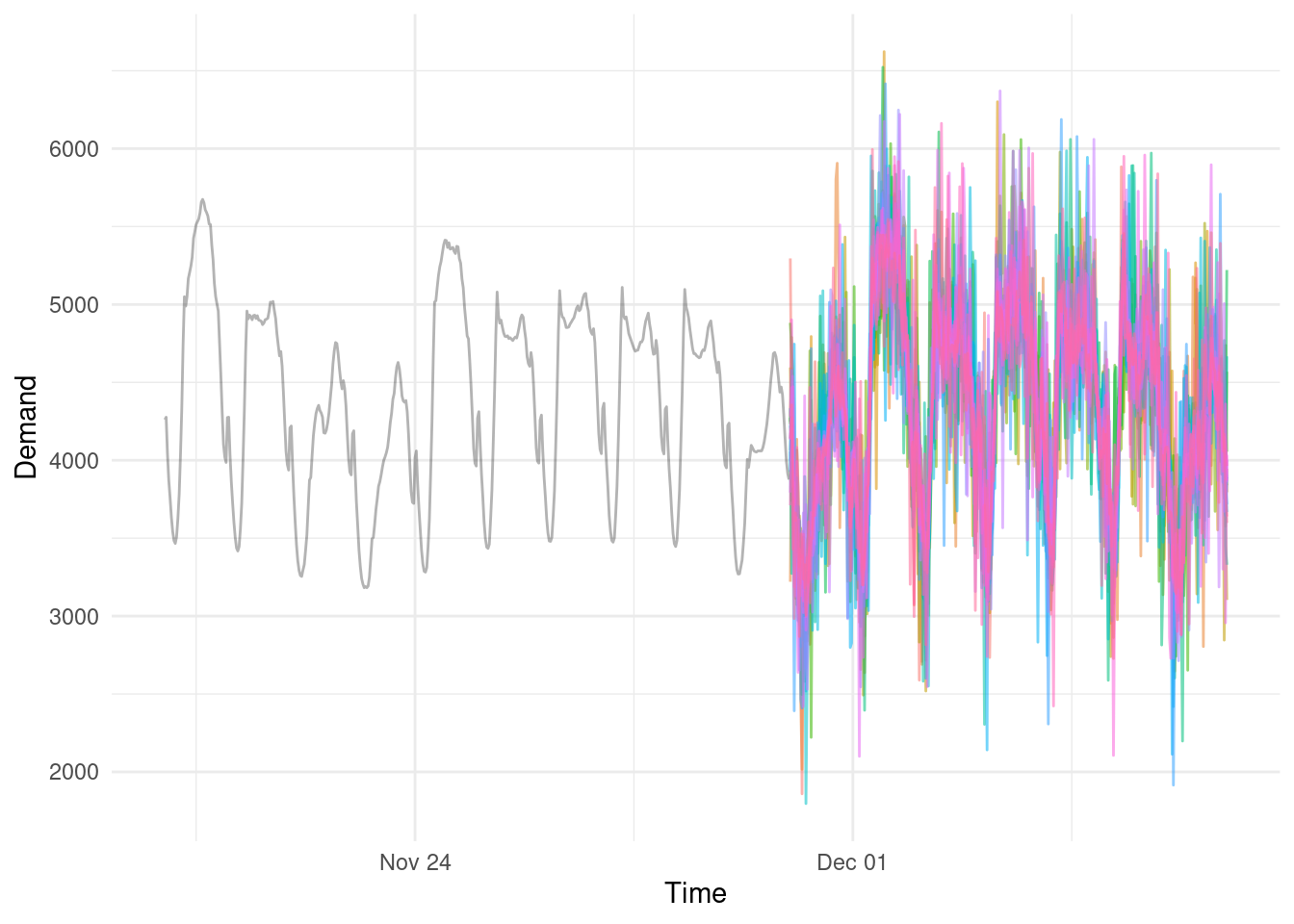
So instead of blindly relying on one (kind of okay looking, but totally unrealistic) forecast, we now have a ‘fuzzy’ region of plausible values.
Ok but why bother?
If you don’t know with certainty what your forecast is going to be, then don’t just give one concrete number. It’s misleading.
Its more important to know how uncertain your forecast is rather than what your forecast is.
You can still pull out a mean or point estimate but by delivering the whole story you are conveying not just what you think is likely to happen, but how certain you are about it.
Often this can lead to more meaningful discussions. Perhaps it’s not the mean of your forecast distribution that you care about, its the extreme values. For example, If I was stress testing business cash flows and forecasting the cost of a maintenance activity, I’d be more interested in forecasting the 95% upper limit of forecast costs rather than the ‘expected’ cost.
In practice, you often don’t have to do any mathematical simulations. Proper time series forecasts have methods to calculate prediction intervals out of the box (see below).
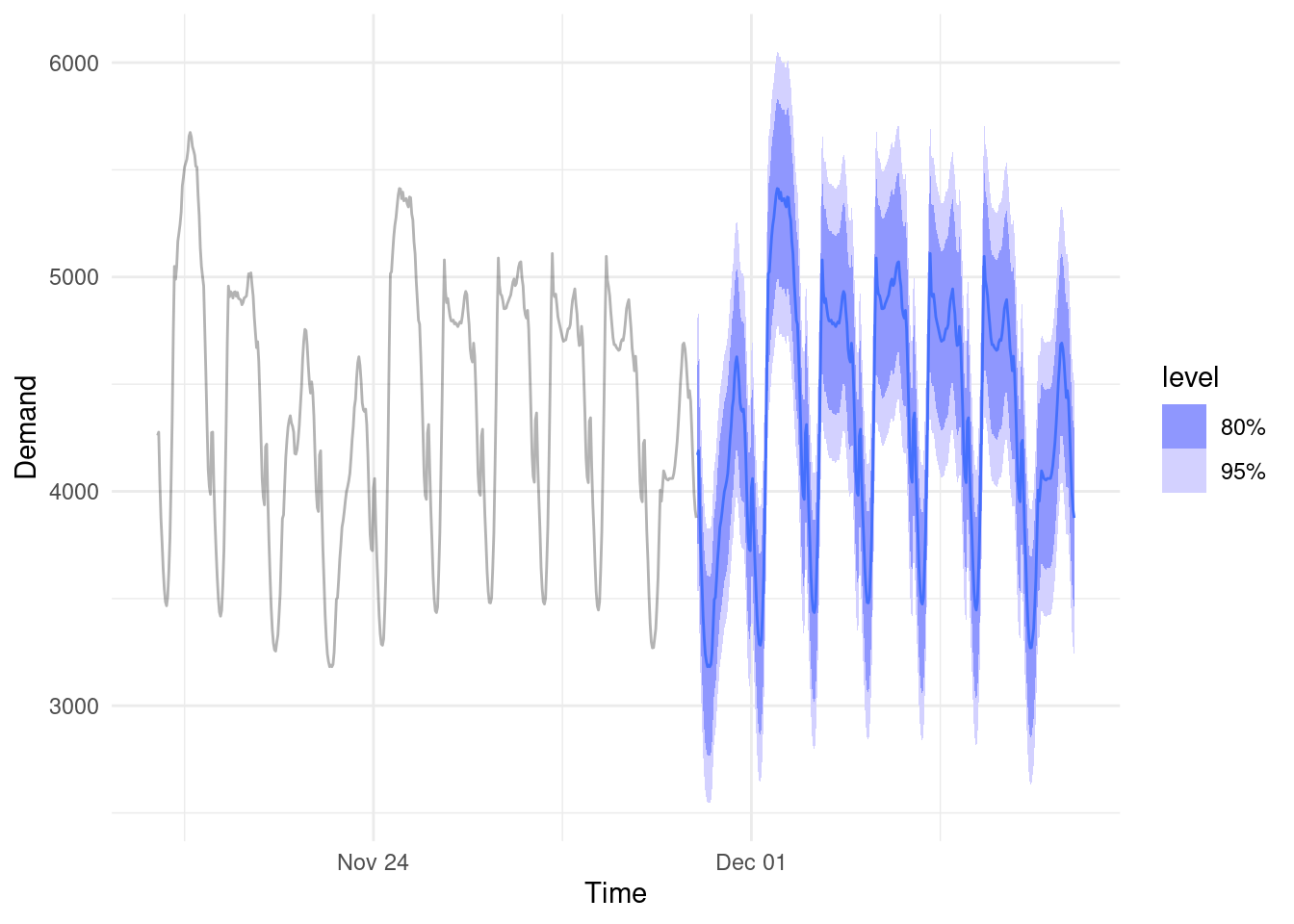
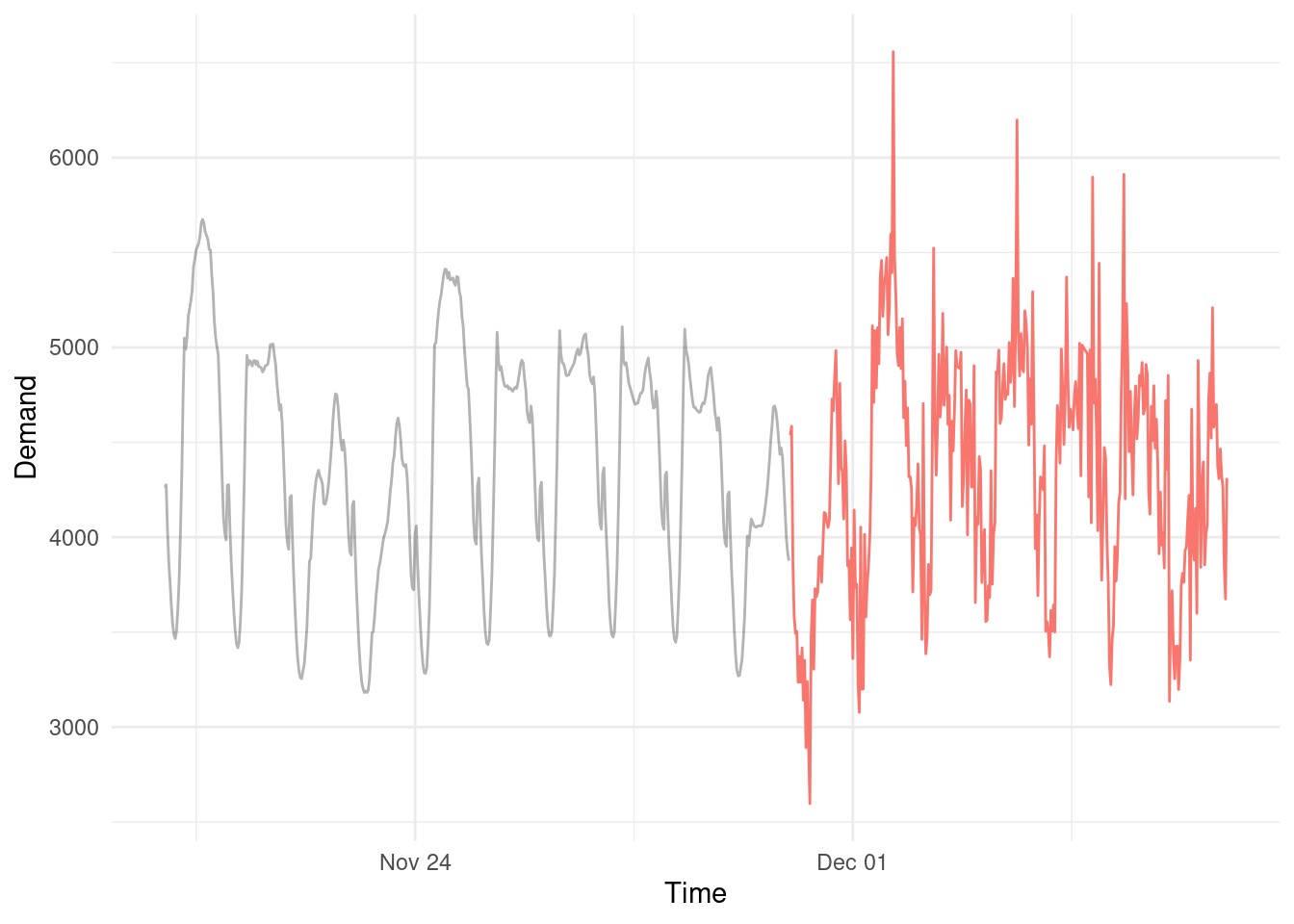
Spoiler
Want to know what actually happened? Here it is in red.
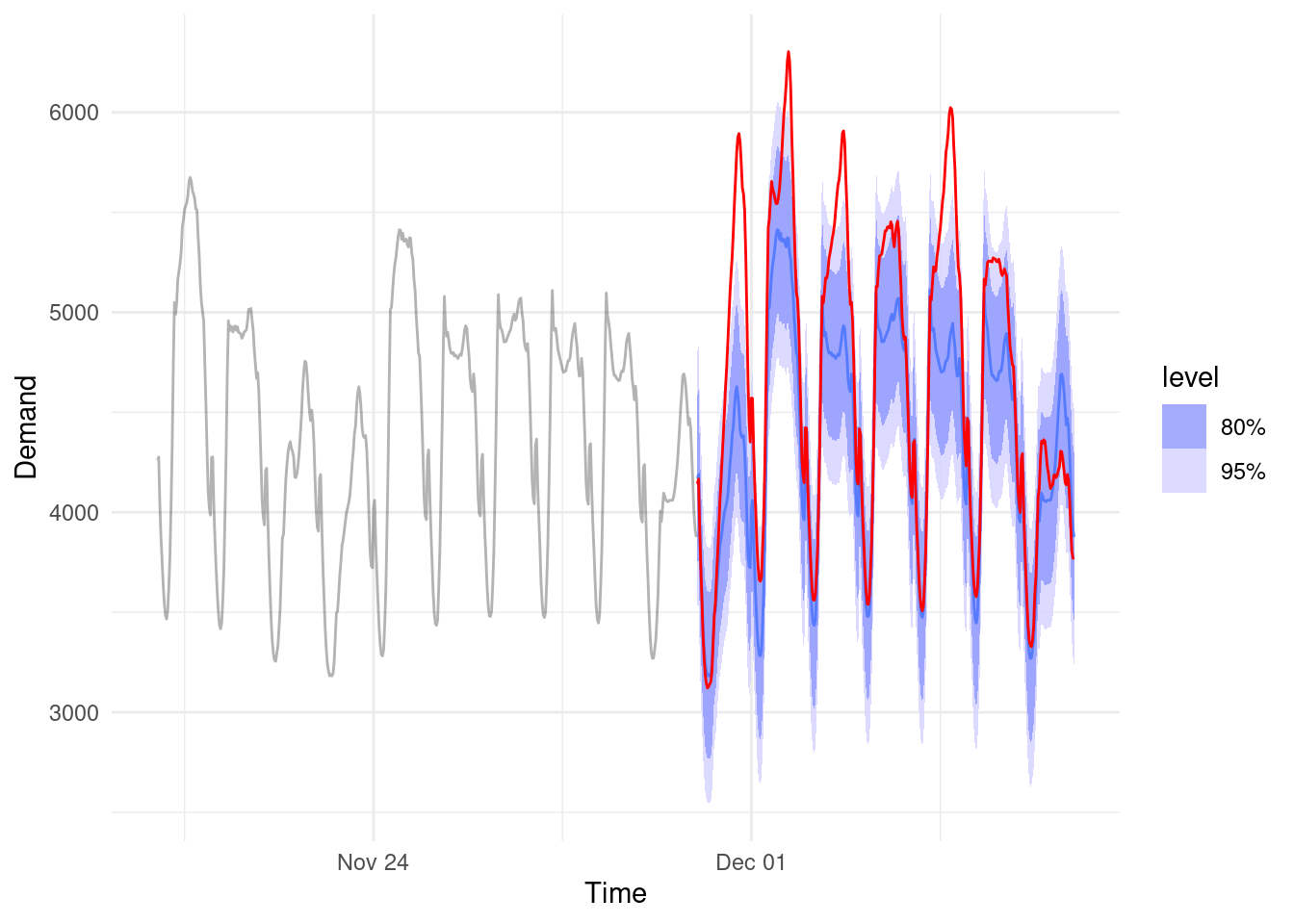
A huge criticism of providing probabilistic forecasts is that is seems like you are ‘hedging your bets’ and being evasive. The reality is, in our electricity example, it was just very hot and demand surged (much higher than even our 95% prediction interval). So if it’s realistic and plausible to see forecast values in these ranges (or even more extreme) - Why wouldn’t you want to include that information in your forecast??
Aside
In practice a statistician will likely use a more sophisticated model than presented here. These models may take into account temperature and other factors but there will still be unexplained variance that will need to be quantified if you want a quality forecast produced.
If you or your organisation want to get serious about making proper forecasts and being proactive when making critical decisions - drop me a line, I can help.
References
O’Hara-Wild M, Hyndman R, Wang E, Godahewa R (2022). tsibbledata: Diverse Datasets for ‘tsibble’. https://tsibbledata.tidyverts.org/, https://github.com/tidyverts/tsibbledata/.
Footnotes
Source: Australian Energy Market Operator. tsibbledata R package.↩︎